Fairbourne Capital · 22 May 2026
AI without your own research is a confident stranger with access to the internet
The case for a knowledge wiki.
Earlier this month EY Canada quietly withdrew a 44-page report on cybersecurity threats in loyalty systems, written to market the firm's services. An external investigation found that most of its cited sources were fabricated, misattributed or pointed to pages that did not exist — footnotes credited to Forbes, McKinsey, Gartner and others that led nowhere when followed.1 The prose itself was fluent and plausible throughout. A reader could not have known it was AI slop, and EY evidently assumed nobody would check for a 44-page report. It was posted last summer, which means it has already been absorbed into the training data for the next generation of models — the fabrication does not just sit in one withdrawn report, it feeds the thing that will write the next one, with no human in the loop to catch it on the way through.
The report failed because it was the output of a prompt with access to the internet and no research underneath. Asked to sound insightful in a niche where it had no good material, the model did the only thing it could and invented some.
What LLMs are and are not built for
We are reaching for LLMs when judgement is required, even though they were never designed for it, because they are efficient. That is sometimes the right call, but it depends on the stakes involved. When the cost of being wrong is a withdrawn marketing report, efficient wins. When the cost is a capital allocation decision, it does not.
When getting it right matters, what matters is whether the work is a task or a job. A task has a defined outcome and frequent checkpoints — write the code, run it, see whether it passes. The signal is immediate and the model can iterate against it without a human in the loop. A job is the opposite end of the same spectrum: it requires a decision before the outcome can be known, and the outcome arrives much later, if it resolves cleanly at all.
Investment management sits at the far end. The work is deciding under uncertainty on incomplete data, where the verdict on today's call may not be known for years. There are few checkpoints and no immediate signals as to which path is better. That is precisely the environment in which a model has nothing to iterate against — and precisely where it will, asked confidently enough, invent the missing material.
Yet most of what is being shipped for the industry today is a thin wrapper on the LLM itself, a domain-specific interface and little beneath it. Our chats and agents behave more like confident-sounding strangers on the internet than like analysts who can show their work.
Whose voice should you weight highest?
Take private credit, where the range of views is wide. The March 2026 market update release from Cliffwater — historically a thought leader and the leading index provider in US private credit, and a house with a position to defend — stated that performance “remains in-line with historical averages” and that credit health was “steady and consistent with previous quarters.”2 This at a point in the cycle marked by gated redemptions, NAV markdowns and dividend cuts at listed BDCs, at least in the vehicles sold to non-institutional money.
Late in a cycle, the industry's own voices are the ones to discount. But which to weight up? Your own prior research, first. Then your team and the people whose judgement you have already tested. A model can do the workflow around this — pull the filing, build the spreadsheet — but it cannot tell you which source deserves the most weight, or whether the analysis is any good. Those are the judgements that compound: what you have read, what you found material, whom you decided to trust, and the record of what you weighted how, and whether it proved right.
That is the asset. It is yours, it cannot be bought off the shelf, and it gets more valuable over time. The industry is racing to put each new frontier model on top of the existing workflow — faster spreadsheets, sharper pattern-matching, more elaborate signal generation. Don't get me wrong, it's also very useful. But the check that would have caught the fabrication in the EY report is not built into the systems being adopted, and the EY report is only the visible version of a failure that is often silent and unnoticed.
Using your own knowledge more wisely
The remedy is not a better prompt. It is to give the model a substrate to stand on: a curated body of material you have decided is worth keeping, with a structure on top that says how much each piece is worth. Deciding what earns a place in the corpus, and at what level of authority per author, is already most of the work — and it is the part that guards against invention.
What goes in:
- Knowledge — the verbatim writing of internal and external authors you have decided are worth tracking
- Past judgements — your own prior writing, the positions you held, the decisions you made
- Experience — team and colleagues' memos, manager DD notes, returned DDQs, draft work
The model's job is then to build the connective tissue: the authority tier on every page, the citation on every claim, the audit trail back to the original passage.3
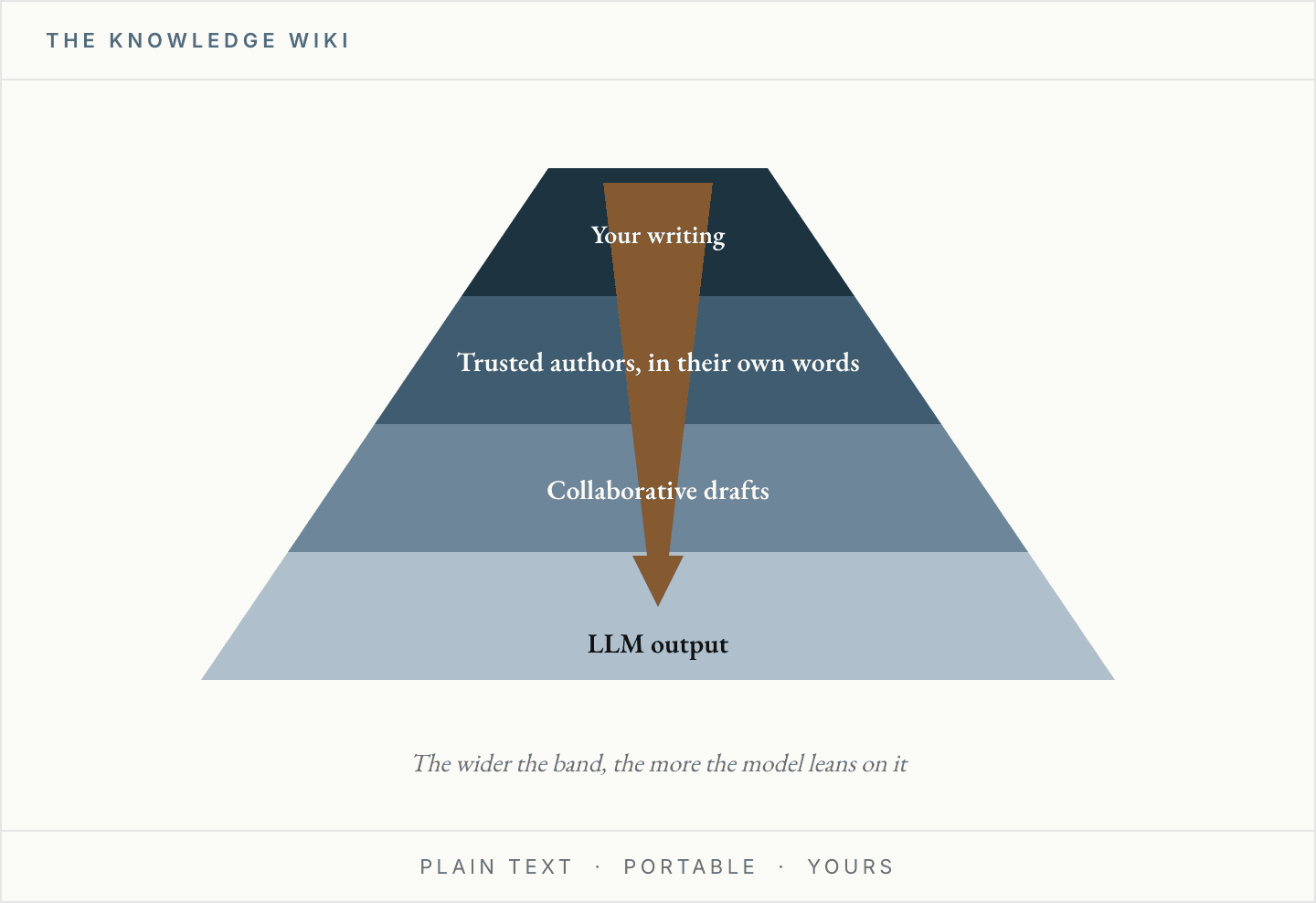
What you get, when you then ask a question, is inference weighted by authority rather than by whatever the internet shouts loudest — and an answer that has to show where each part came from.
A note on incentives
The economics of producing marketing-grade content have collapsed. The discipline of checking it against fabrication, or against data that is simply immaterial, has not kept pace or been prioritised.
For the foundation model companies, it's clear why. Building a verifiable substrate properly puts a human back in the loop, and that is the bottleneck the model companies are least inclined to prize. With hyperscaler capital spending running at roughly $725bn this year, the rational move is to ship agents that capture attention and address tasks, not workflows.4 This is understandable. But for investment work it points exactly the wrong way: the most valuable asset is not the service, it is your own differentiated substrate.
So treat it the way you would treat any compounding asset. Sourcing what you can verify, weighting what you can attribute, and tracking down what you still do not know is not a relic of a slower era. It is the discipline that keeps your own experience from being drowned out by a confident stranger reading the internet.
Notes
- GPTZero, Investigation: Hallucinations in Ernst & Young Report on Loyalty Fraud, 2026. Confirmed by trade press including Computing (UK) and Information Age (Australian Computer Society). EY subsequently withdrew the report and said it was reviewing the circumstances of publication. ↩
- Cliffwater, Cliffwater Direct Lending Index Data Supports Strength of Private Credit, market update release, 31 March 2026. ↩
- On the structure underneath, for those who want it. Four things are non-negotiable. Portable: the substrate is plain text on a local filesystem, no vendor software and no proprietary format. Model-agnostic: the model is a service in front of the substrate, not its container, so models can be swapped without rebuilding. Authority-weighted: every source carries a declared tier, from your own writing down to LLM output, and the hierarchy lives in the metadata rather than in the model's inference. Auditable: every claim resolves to a named passage in a named source, and a claim that cannot resolve is required to say so. In practice each source is held as plain text with its metadata and the author's verbatim passages preserved; retrieval is by meaning rather than keyword, so the model finds the right passage rather than the right phrase; and sources link to one another, building a graph of analytically adjacent material that densifies over time, with older work picking up annotations at lower authority than the original — so the corpus becomes its own record of which voices were right. ↩
- Big-five hyperscaler capital expenditure for 2026, confirmed at roughly $725bn following Q1 2026 earnings, up from the $660–690bn range estimated in February. Goldman Sachs Research; reported by Yahoo Finance, May 2026. ↩
- With thanks to Andrej Karpathy, whose April 2026 “LLM Wiki” gist articulated the plain-text knowledge-substrate pattern this builds on. The adaptation here — authority-weighted retrieval, verbatim preservation, the audit trail — is the asset owner's.